2021. 3. 4. 00:48ㆍ프로그래밍-AI & 빅데이터/머신러닝
<사이킷런 지원 데이터>


보통 위와 같이 import
크게 다섯가지의 속성을 가짐
가장 중요한 data, target은 모두 ndarray 형태의 자료이다
data : 피처 데이터 셋
feature_name: 피처 데이터 셋의 이름
target: classification에서는 라벨 데이터, regression에서는 결과 데이터
target_name: 라벨 데이터 이름
DESCR: 각각에 대한 설명
<Model Selection- 교차검증>
앞서 말했던바와 같이 모델을 학습용, 테스트용으로 분리하거나 튜닝에 사용
특히 overfit을 방지하기 위해 교차검증이 필요
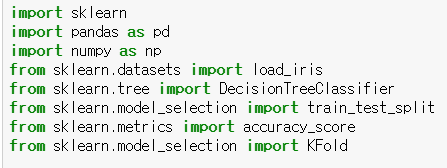


보편적으로 사용되는 K폴드 방식
이는 데이터셋을 K개로 나누어 한개를 검증 세트로 사용하는 것
테스트 데이터셋은 별도로 존재하고, 기존 학습데이터를 K번 쪼개 검증에 이용하는 것이다.
피쳐 데이터 셋, 라벨 셋, 학습엔진을 준비하고, model_selection 라이브러리에서 kfold를 가져온다
split 메소드로 데이터셋을 train과 test로 나눈뒤, 각각 데이터를 분배한다
이후 fit으로 학습을 수행하고, predict으로 결과를 가늠하는데, 이때 index를 넘버를 두어 콘솔에 찍어본다.
넘파이 객체로 리턴된 결과를 찍어보면, 5번의 folding을 진행하며 검증했음을 알 수 있다
하지만 이 방식은 imbalaced한 데이터셋에 대한 적절한 검증방식이라고 할 수 없다
이를 해결하기 위해 원본 데이터의 레이블링 분포를 적절히 고려한 후 폴딩해주는 Stratified K 폴드 방식을 사용한다


인덱싱을 위해 dataframe객체로 결과를 변경하였다.
갯수만 콘솔을 찍어보았더니, 매우 불균형한 검증 데이터가 만들어졌음을 알 수 있다.
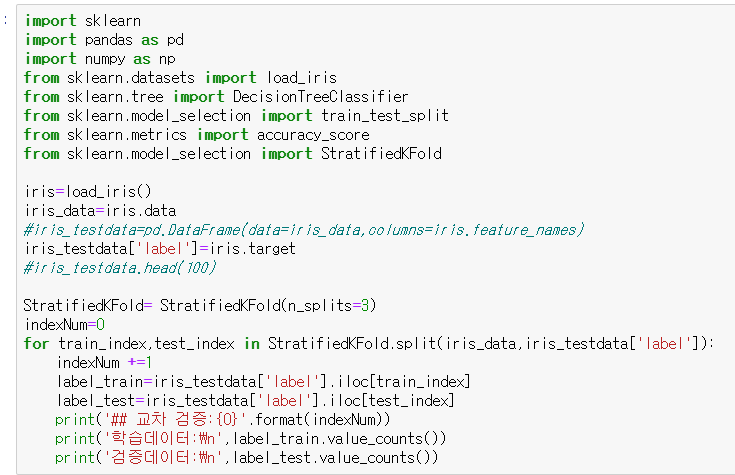
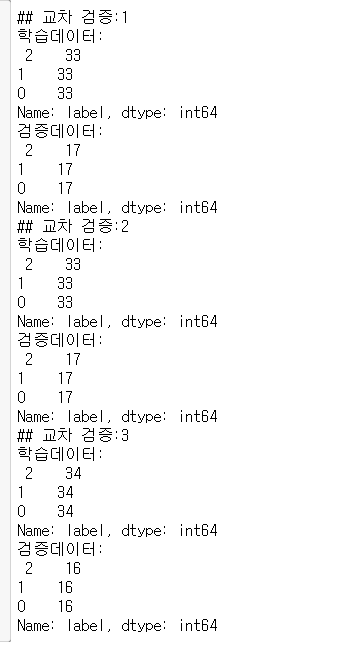
반면 StratifiedKFold를 사용한 결과 분포를 고려한 Folding이 되었음을 알 수 있다.
이 경우엔 피쳐와 라벨 데이터가 모두 필요함을 알 수 있다.


결과는 이렇게 된다.
실제로 classification에서는 stratified K폴드가 사용되고, 회귀에서는 아니다.
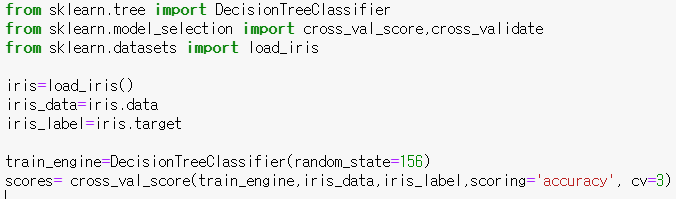
사이킷런에서는 cross_val_score라는 api를 제공한다
이 api는 위에서 짰던 fit, predict, evaluation을 모두 수행해준다
<Model Selection- 하이퍼 파라미터 >
알고리즘에 하이퍼 파라미터를 입력하면서 최적의 파라미터를 찾을 수 있다.
사이킷런은 이 튜닝을 편하게 할 수 있는 api를 제공한다.
GridSearchCV가 바로 그 API이다.
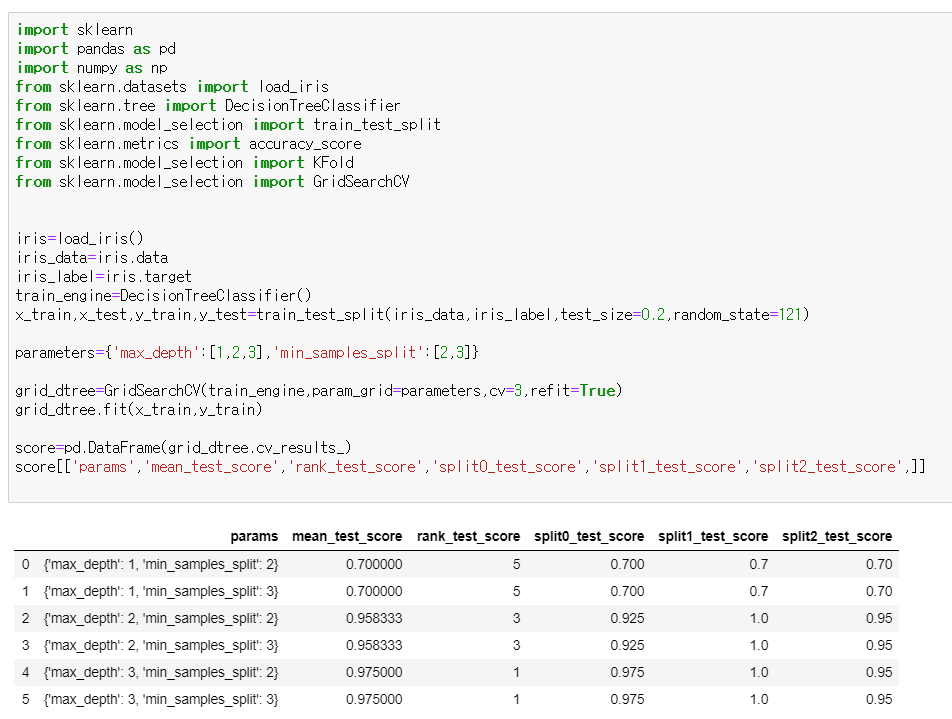
기존에는 paramter를 조합하며 최적의 결과를 찾아야 했다(예시의 경우에는 6번의 시도가 필요하다)
그러나 GridSearchCV를 이용하여 가장 최적의 parameter를 찾아냈다.
이때 rank는 좋은 순서를, score는 평균값을 나타낸다.
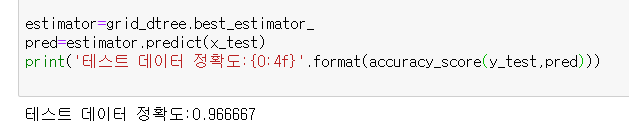
이렇게 최적의 estimator가 정해지만, best_estimater 메소드를 통해 바로 반환받아 사용이 가능하다.
'프로그래밍-AI & 빅데이터 > 머신러닝' 카테고리의 다른 글
| [파이썬 머신러닝] 사이킷런을 이용해 타이타닉 생존자 예측하기 (0) | 2021.03.08 |
|---|---|
| [파이썬 머신러닝] 3. 싸이킷런(3) - 데이터 전처리 (0) | 2021.03.08 |
| [파이썬 머신러닝] 3. 사이킷런 (1) (0) | 2021.02.03 |
| [파이썬 머신러닝] 2. 판다스(2)- 데이터 셀렉션 및 필터링 (0) | 2021.01.25 |
| [파이썬 머신러닝] 2. 판다스(1)- DataFrame의 변환,생성,수정,삭제,인덱스 (0) | 2021.01.13 |