2021. 1. 18. 17:50ㆍ프로그래밍-Science/자료구조
1. 딕셔너리(map)
정의: [key, value] 형태로 원소를 모아놓은 자료구조
특징: set처럼 유일값을 다루지만, [key, value] 형태로 저장한다.
<구현>

2. 해시
[자료구조] 해시테이블(HashTable)이란?
1. 해시테이블(HashTable)이란? [ HashTable(해시테이블)이란? ] 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른
mangkyu.tistory.com
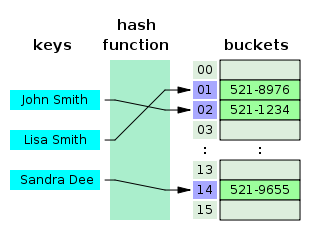
정의:해시 테이블은 [key, value] 형태로 원소를 모아놓은 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는데, 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.
특징: 해시함수 자체를 구현하는 방법은 여러가지가 있다. 주로 하기의 네가지 중 하나가 사용된다.
-
Division Method: 나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다.( 주소 = 입력값 % 테이블의 크기) 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 알려져 있다.
-
Digit Folding: 각 Key의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용하는 방법이다.
-
Multiplication Method: 숫자로 된 Key값 K와 0과 1사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다. h(k)=(kAmod1) × m
-
Univeral Hashing: 다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만드는 기법이다.
<구현>

<해시 충돌>
우연히 해시 함수의 리턴값(인덱스)이 동일한 경우
이러한 경우를 막기 위해 보통 세가지 방법을 사용한다
1) Chaning
- 테이블의 인덱스별로 Linked-List를 생성해 원소를 저장한다
- 해당 방식을 사용하면 같은 index를 갖더라도, 해당 index에 원소라 Linked-List 형태로 여러개가 존재하게 된다.
- 단, 메모리가 추가적으로 소요된다

valuePair라는 객체가 생기고 put 메소드는 다음과 같이 수정된다
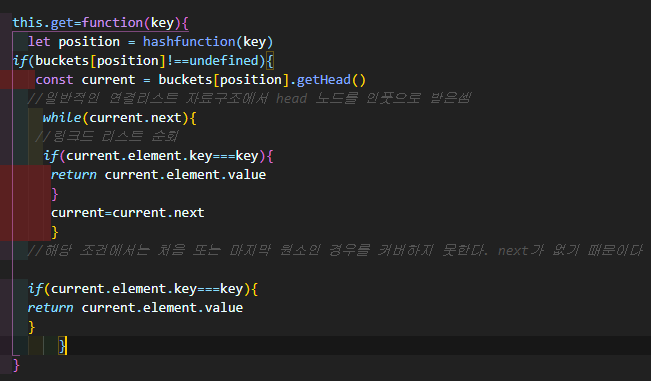
get메소드는 약간 더 복잡하다
remove도 비슷하지만, 원소를 지우고 undefined로 바꾸어야 한다는 점만 다르다
2) Linear probing
- 버킷의 해당 index에 이미 원소가 있다면 +1의 자리를, 그것도 있다면 +2의 자리를 연쇄적으로 찾아본다

put을 이렇게 하면 get 역시 같은 로직을 사용한다
position에 내가 원하는 key-value가 없다면
1을 키운 다음 postion에 있는지 확인하는 과정을 연쇄적으로 진행하도록 만든다
3. 트리
정의: 계층구조를 추상화 한 모델
특징: 노드와 리프로 구성
1) 이진트리
- 노드가 최대 2개의 자식 노드를 갖는 구성
- 우측 노드에 더 큰 값을 배치하면 '이진 탐색 트리(binary search tree)'라고 한다
- LinkedList와 유사하며 각 노드마다 자식노드를 가리키는 포인터가 두개가 있다
- 노드에서 값은 원소가 아닌 key에 있다
<구현>


새 노드를 어디에 추가해야할지 알려주는 insertNode 함수가 필요하다

insert메소드는 root가 없는 경우 insertNode로 넘어가지 않고 root에 배치해야하므로 필요하다
<Traverse(트리순회)>
1) In-order Traversal(중위순회): 작은 값에서 큰 값 방향으로 방문한다. 정렬에 자주 사용한다.

2) pre-order Traversal(전위순회): 자식 노드보다 노드 자신을 먼저 방문한다. 구조화 된 문서 출력에 자주 사용한다.

3) post-order Traversal(후위순회): 자식 노드를 노드 자신보다 먼저 방문한다. 디렉토리와 서브 디렉토리의 파일 용량 계산 때 자주 쓴다.

세가지 방법 모두 로직을 처리하는 순서만 다르다.
<트리 검색>
1) 최솟값, 최댓값 찾기

최댓값은 right 노드를 찾으면 된다
2) 특정값(key) 찾기

3) 특정값(key) 삭제
key를 찾은 후 처리 로직이 약간 까다롭다
- 찾은 키가 리프노드인 경우: 그냥 삭제하고 부모노드의 포인터도 삭제
- 찾은 키가 한쪽에 자식이 있는 경우: 손자노드와 할아버지 노드를 연결해준다
- 찾은 키가 양쪽에 자식이 있는 경우
'프로그래밍-Science > 자료구조' 카테고리의 다른 글
| [trie] Implement Trie (Prefix Tree) (0) | 2021.03.29 |
|---|---|
| [자바스크립트] 연결리스트, 집합 정리 (1) | 2021.01.07 |
| [자바스크립트] 배열, 스택, 큐, 연결 리스트, 집합 정리 (0) | 2021.01.07 |