2021. 1. 14. 09:58ㆍ프로그래밍-Infra/AWS
<RedShift를 활용한 데이터 웨어하우징>
- 정형 데이터 분석 아키텍쳐
- RedShift-SQL Client-PostgreDB-DynamoDB-S3

RedShift:
- 데이터 웨어하우징 관리 시스템
- 클러스터를 생성한 후 사용 시작
- PostGreSQL기반의 DB를 탑재하고 있다
- 대쉬보드를 통해 시각화 된 데이터 분석
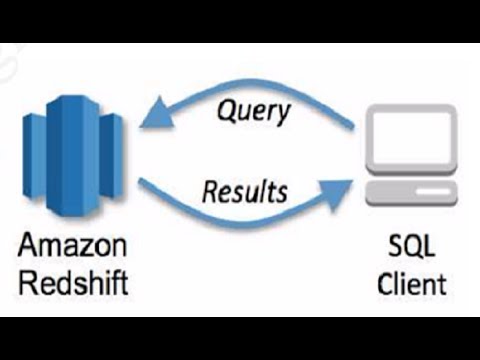
SQL Client
- RedShift에 쿼리로 데이터를 CRUD할 수 있다. Workbench와 같은 역할이다.
Dynamo DB
- 스키마가 없는 NoSQL DB. 데이터가 자동 백업되고, 확장과 배포에 용이하다.
- key-value로 구성된 Item이 하나의 원소이고, 이들이 모여 Table을 이룬다.
- 기본적으로 테이블 인덱스가 발급되는데, 이를 사용하여 검색을 진행한다.
- 같은 NoSQL인 MongoDB에 비해 Saas 그 자체이므로 알아서 스케일 조정이나 부하 처리가 되니까 좋은듯
FlyData Sync
- 데이터 입력을 다수의 사용자가 하게 되면 데이터 정합성에 문제가 생김
- 얘가 그걸 맞춰줌. DB와 RedShift간의 싱크를 맞춰준다.
<사용방식>
1. 클러스터 생성
2. SQL 클라이언트(workbench)와 연결
3-1. 쿼리로 데이터 생성
3-2. 대용량 데이터의 경우 S3나 Dynamo DB에서 로딩
4. 대쉬보드를 통한 분석
<Public Data 가져오기>
- 공적으로 공개되는 Public Data들은 엑셀, CSV형식으로 S3에 저장이 가능
- RedShift에서 접근이 가능하다
'프로그래밍-Infra > AWS' 카테고리의 다른 글
| [AWS 구축 패턴] 2. 스토리지 시스템 (0) | 2021.01.13 |
|---|---|
| [AWS 구축 패턴] 1. 웹사이트 (0) | 2021.01.08 |
| [AWS] AWS 제공 Storage별 차이 (0) | 2021.01.08 |